深入了解Redis主从同步:高性能数据复制的利器

引言
Redis作为一种高性能的Key/Value形式的非关系型数据库,被广泛应用于各种场景,包括缓存、会话存储、消息队列等。它以其快速、可靠和灵活的特性,成为了许多应用程序的首选。
然而,随着应用规模的不断扩大和用户访问量的增加,单个Redis实例可能无法满足高并发和高可用的需求。为了解决这个问题,Redis引入了主从同步(Master-Slave Replication)机制,提供了一种简单而有效的方式来实现数据的复制和故障恢复。
在本篇博客中,我们将深入探究Redis主从同步的配置和工作原理。我们将会详细介绍如何配置Redis主从模式,并解释主从同步的优点和缺点。了解这些内容将帮助你更好地理解Redis主从同步的背后机制,并为你构建可靠、高效的Redis集群提供指导。
接下来,我们将分析主从同步的优点,包括高性能的读操作、数据冗余和故障恢复等。同时,我们也会探讨主从同步的潜在缺点,例如主从延迟、网络带宽消耗等。通过全面了解主从同步的优缺点,你将能够更好地权衡使用主从同步来提高系统性能和可用性的决策。
通过阅读本篇博客,你将对Redis主从同步有一个全面的了解,能够更好地应用它来提升应用程序的性能和可用性。无论你是一名开发人员、系统管理员还是架构师,都能从中获得有价值的知识和实践经验。
让我们一起深入了解Redis主从同步的魅力,为你的应用程序带来更高的性能和可靠性吧!
主从架构
Redis 主从架构是一种常用的数据复制机制,它采用主节点和从节点的组合来实现数据的高性能读写和高可用性。主节点负责接收写操作(新增、更新、删除)并维护数据的一致性,而从节点通过复制主节点的数据来提供高效的读取服务。
主从架构的特点如下:
- 高性能读取:通过将读请求分发到从节点上,主节点可以专注于处理写请求,从而提高整个系统的负载能力和读取性能。
- 数据冗余和备份:从节点复制主节点的数据,可以提供数据的冗余和备份。在主节点发生故障时,从节点可以接管服务并保证数据的可用性。
- 故障恢复:当主节点发生故障时,从节点可以选举出一个新的主节点,使系统能够继续提供服务并保持高可用性。
- 横向扩展:通过添加更多的从节点,可以实现系统的横向扩展。从节点可以同时处理更多的读请求,并提供更高的读取性能和容量。
- 灵活性:在主从架构中,可以根据需要配置不同数量的从节点,并根据实际情况调整复制的拓扑结构,以满足不同的业务需求。
配置过程
首先打开从Redis的配置文件,搜索replicaof选项,需要注意的是,在Redis5.0之前,主从配置使用的是slaveof,其配置的格式如下:
1 | replicaof <masterip> <masterport> |
为了演示,博主这边的在本地放了两份Redis,主Redis的端口号为6379,从Redis的端口号为:6380,按照上述配置,我更改了从Redis中配置文件:
1 | replicaof 127.0.0.1 6379 |
如果主
Redis设置了密码,还需要在从Redis中指定主Redis的密码,格式为:masterauth <master-password>
接下来依次启动主\从Redis即可
主:
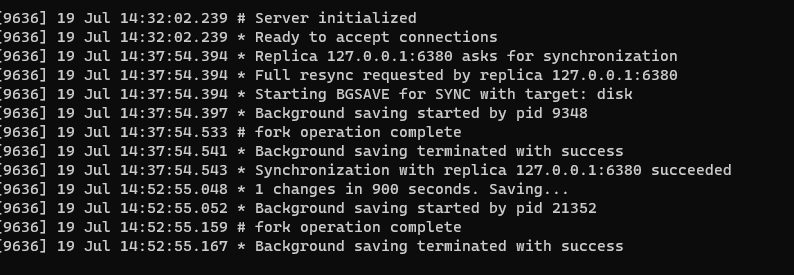
从:
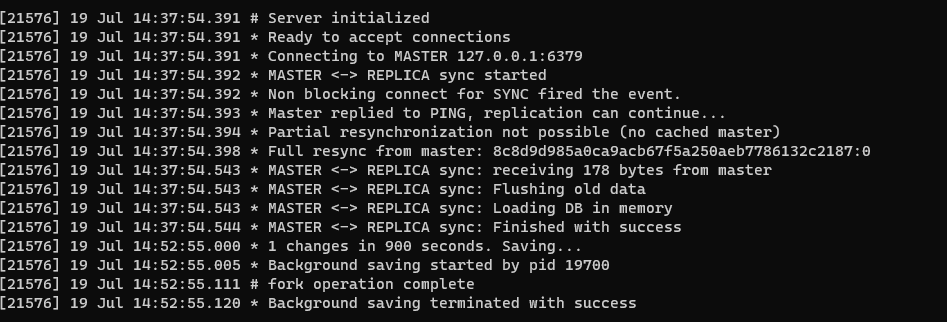
简单对上面两个图进行一下备注
1 | 主: |
启动成功后就可以尝试在主Redis中set一个值,并尝试在从Redis中读取主中设置的值,你可以尽情尝试一下啦,对了,可以在从中使用slaveof no one命令来主动断开主从连接
主从复制原理
主从复制的基本过程有如下几个步骤:
- 同步初始化,也叫全量同步(Full Resynchronization),当前从节点会向主节点发送SYNC命令,请求全量同步,主节点收到SYNC命令后,会执行bgsave命令生成RDB快照,并将快照文件发送给从节点。从节点接收到快照文件后,会先清空自己的数据库,然后加载其中的数据。
- 增量同步,在同步初始化完成后,主节点会将自己的写操作记录为命令,并将这些命令发送给从节点。从节点接收到命令后,会按照顺序执行这些命令,以保持与主节点的数据一致,这个过程主要包括两个步骤:
a. 主节点将所有的写命令发送给从节点,从节点会一一执行这些写命令。
b. 从节点每执行一个写命令,就会给主节点发送ACK命令,表示已完成该命令的执行。主节点会记录从节点执行的偏移量。
通过这个快照同步过程,从节点将能够在与主节点的数据保持一致后,提供与主节点相同的数据服务。 - 增量复制,快照同步完成后,主从复制进入增量复制阶段。在增量复制阶段,主节点会将每个新的写命令实时发送给从节点,确保数据的同步和一致性。
增量复制的工作原理如下:
a. 主节点在每次接收到写命令后,都会将该写命令发送给所有连接的从节点。
b. 从节点接收到写命令后,立即执行,并在执行完成后给主节点发送ACK信号。
c. 主节点根据从节点的ACK信号,记录从节点的执行偏移量,并定期确认哪些数据可以被删除。
通过这个增量复制的过程,主从节点之间能够保持数据的高度一致性,同时从节点可以及时更新数据,以提供读取请求的服务。
缺点
Redis 主从复制虽然提供了一些重要的优势和功能,但也存在一些潜在的缺点,包括:
- 数据同步延迟:
- 主从配置中,从节点需要从主节点复制数据,而复制的过程需要一定的时间。这可能导致从节点上的数据存在一定的延迟,无法实时保持与主节点数据的完全一致性。
- 网络带宽消耗:
- 数据的复制和传输需要占用一定的网络带宽资源。如果有大量的写入操作或者数据量较大,可能会对网络带宽造成负担。
- 主节点单点故障:
- 在主从配置中,如果主节点发生故障,需要手动或通过哨兵进行故障恢复。这可能导致一段时间的服务中断和数据不能实时更新。
- 扩展性限制:
- 主从配置在水平扩展方面存在一定的限制。虽然可以通过增加更多的从节点来提高读取性能和容量,但对于写入操作,仍然需要依赖单个主节点。
总结
Redis 主从同步是一种数据复制机制,主要通过主节点和从节点的组合来实现数据的高性能读写和高可用性。主节点负责处理所有写操作,而从节点通过复制主节点的数据来提供高效的读取服务。
Redis 主从同步的优点包括:
- 高性能的读操作:通过将读请求分发到从节点上,主节点可以专注于处理写请求,提高整个系统的负载能力和读取性能。
- 数据冗余和备份:从节点复制主节点的数据,提供数据的冗余和备份,以保证数据的可用性。
- 横向扩展:通过添加更多的从节点,系统能够横向扩展,提高读取性能和容量。
然而,主从同步也存在一些潜在的缺点和挑战,例如主从延迟、网络带宽消耗等。在使用主从同步时,需要根据实际需求进行配置和管理。
如果你对哨兵模式感兴趣,哨兵模式提供了故障检测和故障转移的功能,可以确保 Redis 高可用性。在哨兵模式中,哨兵节点会检测主节点的状态,并在主节点宕机时自动进行故障转移,选举新的主节点。这种机制可以提供故障恢复的能力,并保证 Redis 在主节点故障时仍然可用。
希望本文总结对你有帮助!如果你还有其他问题或需要进一步的帮助,请随时告知。祝你的博客写作顺利!